2015
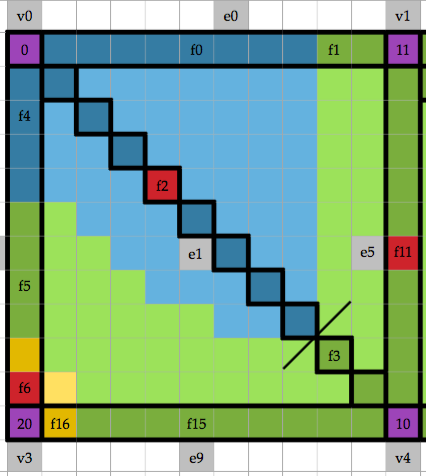
Carr, Hamish; Sewell, Christopher; Lo, Li-Ta; james Ahrens,
Hybrid Data-Parallel Contour Tree Computation Proceedings Article
In: 2015, (LA-UR-15-24759).
Abstract | Links | BibTeX | Tags: and object reppresentations, computational geometry and object modeling, contour tree, data-parallel, gpu, multi-core, nvidia thrust, simulation output analysis, solid, surface, topological analysis
@inproceedings{Carr2015,
title = {Hybrid Data-Parallel Contour Tree Computation},
author = {Hamish Carr and Christopher Sewell and Li-Ta Lo and james Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/HybridData-ParallelContourTreeComputaion.pdf},
year = {2015},
date = {2015-01-01},
number = {LA-UR-15-24759},
institution = {Los Alamos National Laboratory},
abstract = {As data sets increase in size beyond the petabyte, it is increasingly important to have automated methods for data analysis and visualization. While topological analysis tools such as the contour tree and Morse-Smale complex are now well established, there is still a shortage of efficient parallel algorithms for their computation, in particular for massively data-parallel computation on a SIMD model. We report the first data-parallel algorithm for computing the fully augmented contour tree, using a quantized computation model. We then extend this to provide a hybrid data-parallel / distributed algorithm allowing scaling beyond a single GPU or CPU, and provide results for its computation. Our implementation uses the portable data-parallel primitives provided by Nvidia’s Thrust library, allowing us to compile our same code for both GPUs and multi-core CPUs.},
note = {LA-UR-15-24759},
keywords = {and object reppresentations, computational geometry and object modeling, contour tree, data-parallel, gpu, multi-core, nvidia thrust, simulation output analysis, solid, surface, topological analysis},
pubstate = {published},
tppubtype = {inproceedings}
}
2013
Sewell, Christopher; Lo, Li-ta; Ahrens, James
Portable data-parallel visualization and analysis in distributed memory environments Proceedings Article
In: Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on, pp. 25–33, IEEE 2013, (LA-UR-13-23809).
Abstract | Links | BibTeX | Tags: analysis, Concurrent Programming, data-parallel, distributed memory, parallel programming, PISTON, visualization
@inproceedings{sewell2013portable,
title = {Portable data-parallel visualization and analysis in distributed memory environments},
author = {Christopher Sewell and Li-ta Lo and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/PortableData-ParallelVisualizationAndAnalysisInDistributedMemoryEnvironments.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on},
pages = {25--33},
organization = {IEEE},
abstract = {Data-parallelism is a programming model that maps well to architectures with a high degree of concurrency. Algorithms written using data-parallel primitives can be easily ported to any architecture for which an implementation of these primitives exists, making efficient use of the available parallelism on each. We have previously published results demonstrating our ability to compile the same data-parallel code for several visualization algorithms onto different on-node parallel architectures (GPUs and multi-core CPUs) using our extension of NVIDIAÕs Thrust library. In this paper, we discuss our extension of Thrust to support concurrency in distributed memory environments across multiple nodes. This enables the application developer to write data-parallel algorithms while viewing the data as single, long vectors, essentially without needing to explicitly take into consideration whether the values are actually distributed across nodes. Our distributed wrapper for Thrust handles the communication in the backend using MPI, while still using the standard Thrust library to take advantage of available on-node parallelism. We describe the details of our distributed implementations of several key data-parallel primitives, including scan, scatter/ gather, sort, reduce, and upper/lower bound. We also present two higher-level distributed algorithms developed using these primitives: isosurface and KD-tree construction. Finally, we provide timing results demonstrating the ability of these algorithms to take advantage of available parallelism on nodes and across multiple nodes, and discuss scaling limitations for communication-intensive algorithms such as KD-tree construction.},
note = {LA-UR-13-23809},
keywords = {analysis, Concurrent Programming, data-parallel, distributed memory, parallel programming, PISTON, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
2012
Sewell, Christopher; Meredith, Jeremy; Moreland, Kenneth; Peterka, Tom; DeMarle, David; Lo, Li-ta; Ahrens, James; Maynard, Robert; Geveci, Berk
The SDAV software frameworks for visualization and analysis on next-generation multi-core and many-core architectures Proceedings Article
In: High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:, pp. 206–214, IEEE 2012, (LA-UR-12-26928).
Abstract | Links | BibTeX | Tags: data-parallel, in-situ, many-core architectures, mult-core architectures, visualization, VTK-m
@inproceedings{sewell2012sdav,
title = {The SDAV software frameworks for visualization and analysis on next-generation multi-core and many-core architectures},
author = {Christopher Sewell and Jeremy Meredith and Kenneth Moreland and Tom Peterka and David DeMarle and Li-ta Lo and James Ahrens and Robert Maynard and Berk Geveci},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/TheSDAVSoftwareFrameworksForVisualizationAndAnalysisOnNext-GenerationMulti-CoreAndMany-CoreArchitectures.pdf},
year = {2012},
date = {2012-01-01},
booktitle = {High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:},
pages = {206--214},
organization = {IEEE},
abstract = {This paper surveys the four software frameworks being developed as part of the visualization pillar of the SDAV (Scalable Data Management, Analysis, and Visualization) Institute, one of the SciDAC (Scientific Discovery through Advanced Computing) Institutes established by the ASCR (Advanced Scientific Computing Research) Program of the U.S. Department of Energy. These frameworks include EAVL (Extreme-scale Analysis and Visualization Library), Dax (Data Analysis at Extreme), DIY (Do It Yourself), and PISTON. The objective of these frameworks is to facilitate the adaptation of visualization and analysis algorithms to take advantage of the available parallelism in emerging multi-core and manycore hardware architectures, in anticipation of the need for such algorithms to be run in-situ with LCF (leadership-class facilities) simulation codes on supercomputers.},
note = {LA-UR-12-26928},
keywords = {data-parallel, in-situ, many-core architectures, mult-core architectures, visualization, VTK-m},
pubstate = {published},
tppubtype = {inproceedings}
}
2007
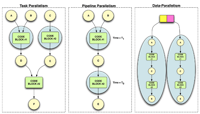
McCormick, Patrick; Inman, Jeff; Ahrens, James; Mohd-Yusof, Jamaludin; Roth, Greg; Cummins, Sharen
Scout: a data-parallel programming language for graphics processors Journal Article
In: Parallel Computing, vol. 33, no. 10, pp. 648–662, 2007, (LA-UR-07-2094).
Abstract | Links | BibTeX | Tags: data-parallel, Graphics Systems
@article{mccormick2007scout,
title = {Scout: a data-parallel programming language for graphics processors},
author = {Patrick McCormick and Jeff Inman and James Ahrens and Jamaludin Mohd-Yusof and Greg Roth and Sharen Cummins},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/ScoutADataParallelProgrammingLanguageForGraphicsProcessors.pdf},
year = {2007},
date = {2007-01-01},
journal = {Parallel Computing},
volume = {33},
number = {10},
pages = {648--662},
publisher = {Elsevier},
abstract = {Commodity graphics hardware has seen incredible growth in terms of performance, programmability, and arithmetic precision. Even though these trends have been primarily driven by the entertainment industry, the price-to-performance ratio of graphics processors (GPUs) has attracted the attention of many within the high-performance computing community. While the performance of the GPU is well suited for computational science, the programming interface, and several hardware limitations, have prevented their wide adoption. In this paper we present Scout, a data-parallel programming language for graphics processors that hides the nuances of both the underlying hardware and supporting graphics software layers. In addition to general-purpose programming constructs, the language provides extensions for scientific visualization operations that support the exploration of existing or computed data sets.},
note = {LA-UR-07-2094},
keywords = {data-parallel, Graphics Systems},
pubstate = {published},
tppubtype = {article}
}
1995
Ahrens, James; Hansen, Charles
Cost-effective data-parallel load balancing Proceedings Article
In: ICPP (2), pp. 218–221, 1995, (LA-UR-95-1462).
Abstract | Links | BibTeX | Tags: data-parallel, load balancing
@inproceedings{ahrens1995cost,
title = {Cost-effective data-parallel load balancing},
author = {James Ahrens and Charles Hansen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/Cost-EffectiveData-ParallelLoadBalancing.pdf},
year = {1995},
date = {1995-01-01},
booktitle = {ICPP (2)},
pages = {218--221},
abstract = {Load balancing algorithms improve a program’s performance on unbalanced datasets, but can degrade performance on balanced datasets, because unnecessary load redistributions occur. This paper presents a cost-effective data-parallel load balancing algorithm which performs load redistributions only when the possible savings outweigh the redistribution costs. Experiment s with a data-parallel polygon renderer show a performance improvement of up to a factor of 33 on unbalanced datasets and a maximum performance loss of only 27 percent on balanced datasets when using this algorithm.},
note = {LA-UR-95-1462},
keywords = {data-parallel, load balancing},
pubstate = {published},
tppubtype = {inproceedings}
}
1993

Ortega, Frank; Hansen, Charles; Ahrens, James
Fast Data Parallel Polygon Rendering Proceedings Article
In: Proceedings of the 1993 ACM/IEEE Conference on Supercomputing, pp. 709–718, ACM, Portland, Oregon, USA, 1993, ISBN: 0-8186-4340-4, (LA-UR-93-3173).
Abstract | Links | BibTeX | Tags: data-parallel, polygon rendering
@inproceedings{Ortega:1993:FDP:169627.169820,
title = {Fast Data Parallel Polygon Rendering},
author = {Frank Ortega and Charles Hansen and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/FastDataParellelPolygonRendering.pdf
http://doi.acm.org/10.1145/169627.169820},
doi = {10.1145/169627.169820},
isbn = {0-8186-4340-4},
year = {1993},
date = {1993-01-01},
booktitle = {Proceedings of the 1993 ACM/IEEE Conference on Supercomputing},
pages = {709--718},
publisher = {ACM},
address = {Portland, Oregon, USA},
series = {Supercomputing '93},
abstract = {This paper describes a parallel method for polygonal rendering ona massively pamliel SIMD machine. This method, hazed on a simple shading model, is taqeted for applications which require very fad polygon rendering for extremely large sets of polygons such as is found in many scientific visualization applications, The algorithms described in this paper are incorpomted into a library of 9D gmphics routines written for the Connection Machine. The routines am implemented on both the CM-ZOO and the CM-5. This libmry enables a acientid to display $D shaded polygons directly jhm a pamllel machine without the need to tmnamit huge amounts of data to a pod-processing rendering system.},
note = {LA-UR-93-3173},
keywords = {data-parallel, polygon rendering},
pubstate = {published},
tppubtype = {inproceedings}
}
Carr, Hamish; Sewell, Christopher; Lo, Li-Ta; james Ahrens,
Hybrid Data-Parallel Contour Tree Computation Proceedings Article
In: 2015, (LA-UR-15-24759).
@inproceedings{Carr2015,
title = {Hybrid Data-Parallel Contour Tree Computation},
author = {Hamish Carr and Christopher Sewell and Li-Ta Lo and james Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/HybridData-ParallelContourTreeComputaion.pdf},
year = {2015},
date = {2015-01-01},
number = {LA-UR-15-24759},
institution = {Los Alamos National Laboratory},
abstract = {As data sets increase in size beyond the petabyte, it is increasingly important to have automated methods for data analysis and visualization. While topological analysis tools such as the contour tree and Morse-Smale complex are now well established, there is still a shortage of efficient parallel algorithms for their computation, in particular for massively data-parallel computation on a SIMD model. We report the first data-parallel algorithm for computing the fully augmented contour tree, using a quantized computation model. We then extend this to provide a hybrid data-parallel / distributed algorithm allowing scaling beyond a single GPU or CPU, and provide results for its computation. Our implementation uses the portable data-parallel primitives provided by Nvidia’s Thrust library, allowing us to compile our same code for both GPUs and multi-core CPUs.},
note = {LA-UR-15-24759},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Sewell, Christopher; Lo, Li-ta; Ahrens, James
Portable data-parallel visualization and analysis in distributed memory environments Proceedings Article
In: Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on, pp. 25–33, IEEE 2013, (LA-UR-13-23809).
@inproceedings{sewell2013portable,
title = {Portable data-parallel visualization and analysis in distributed memory environments},
author = {Christopher Sewell and Li-ta Lo and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/PortableData-ParallelVisualizationAndAnalysisInDistributedMemoryEnvironments.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on},
pages = {25--33},
organization = {IEEE},
abstract = {Data-parallelism is a programming model that maps well to architectures with a high degree of concurrency. Algorithms written using data-parallel primitives can be easily ported to any architecture for which an implementation of these primitives exists, making efficient use of the available parallelism on each. We have previously published results demonstrating our ability to compile the same data-parallel code for several visualization algorithms onto different on-node parallel architectures (GPUs and multi-core CPUs) using our extension of NVIDIAÕs Thrust library. In this paper, we discuss our extension of Thrust to support concurrency in distributed memory environments across multiple nodes. This enables the application developer to write data-parallel algorithms while viewing the data as single, long vectors, essentially without needing to explicitly take into consideration whether the values are actually distributed across nodes. Our distributed wrapper for Thrust handles the communication in the backend using MPI, while still using the standard Thrust library to take advantage of available on-node parallelism. We describe the details of our distributed implementations of several key data-parallel primitives, including scan, scatter/ gather, sort, reduce, and upper/lower bound. We also present two higher-level distributed algorithms developed using these primitives: isosurface and KD-tree construction. Finally, we provide timing results demonstrating the ability of these algorithms to take advantage of available parallelism on nodes and across multiple nodes, and discuss scaling limitations for communication-intensive algorithms such as KD-tree construction.},
note = {LA-UR-13-23809},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Sewell, Christopher; Meredith, Jeremy; Moreland, Kenneth; Peterka, Tom; DeMarle, David; Lo, Li-ta; Ahrens, James; Maynard, Robert; Geveci, Berk
The SDAV software frameworks for visualization and analysis on next-generation multi-core and many-core architectures Proceedings Article
In: High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:, pp. 206–214, IEEE 2012, (LA-UR-12-26928).
@inproceedings{sewell2012sdav,
title = {The SDAV software frameworks for visualization and analysis on next-generation multi-core and many-core architectures},
author = {Christopher Sewell and Jeremy Meredith and Kenneth Moreland and Tom Peterka and David DeMarle and Li-ta Lo and James Ahrens and Robert Maynard and Berk Geveci},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/TheSDAVSoftwareFrameworksForVisualizationAndAnalysisOnNext-GenerationMulti-CoreAndMany-CoreArchitectures.pdf},
year = {2012},
date = {2012-01-01},
booktitle = {High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:},
pages = {206--214},
organization = {IEEE},
abstract = {This paper surveys the four software frameworks being developed as part of the visualization pillar of the SDAV (Scalable Data Management, Analysis, and Visualization) Institute, one of the SciDAC (Scientific Discovery through Advanced Computing) Institutes established by the ASCR (Advanced Scientific Computing Research) Program of the U.S. Department of Energy. These frameworks include EAVL (Extreme-scale Analysis and Visualization Library), Dax (Data Analysis at Extreme), DIY (Do It Yourself), and PISTON. The objective of these frameworks is to facilitate the adaptation of visualization and analysis algorithms to take advantage of the available parallelism in emerging multi-core and manycore hardware architectures, in anticipation of the need for such algorithms to be run in-situ with LCF (leadership-class facilities) simulation codes on supercomputers.},
note = {LA-UR-12-26928},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
McCormick, Patrick; Inman, Jeff; Ahrens, James; Mohd-Yusof, Jamaludin; Roth, Greg; Cummins, Sharen
Scout: a data-parallel programming language for graphics processors Journal Article
In: Parallel Computing, vol. 33, no. 10, pp. 648–662, 2007, (LA-UR-07-2094).
@article{mccormick2007scout,
title = {Scout: a data-parallel programming language for graphics processors},
author = {Patrick McCormick and Jeff Inman and James Ahrens and Jamaludin Mohd-Yusof and Greg Roth and Sharen Cummins},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/ScoutADataParallelProgrammingLanguageForGraphicsProcessors.pdf},
year = {2007},
date = {2007-01-01},
journal = {Parallel Computing},
volume = {33},
number = {10},
pages = {648--662},
publisher = {Elsevier},
abstract = {Commodity graphics hardware has seen incredible growth in terms of performance, programmability, and arithmetic precision. Even though these trends have been primarily driven by the entertainment industry, the price-to-performance ratio of graphics processors (GPUs) has attracted the attention of many within the high-performance computing community. While the performance of the GPU is well suited for computational science, the programming interface, and several hardware limitations, have prevented their wide adoption. In this paper we present Scout, a data-parallel programming language for graphics processors that hides the nuances of both the underlying hardware and supporting graphics software layers. In addition to general-purpose programming constructs, the language provides extensions for scientific visualization operations that support the exploration of existing or computed data sets.},
note = {LA-UR-07-2094},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Ahrens, James; Hansen, Charles
Cost-effective data-parallel load balancing Proceedings Article
In: ICPP (2), pp. 218–221, 1995, (LA-UR-95-1462).
@inproceedings{ahrens1995cost,
title = {Cost-effective data-parallel load balancing},
author = {James Ahrens and Charles Hansen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/Cost-EffectiveData-ParallelLoadBalancing.pdf},
year = {1995},
date = {1995-01-01},
booktitle = {ICPP (2)},
pages = {218--221},
abstract = {Load balancing algorithms improve a program’s performance on unbalanced datasets, but can degrade performance on balanced datasets, because unnecessary load redistributions occur. This paper presents a cost-effective data-parallel load balancing algorithm which performs load redistributions only when the possible savings outweigh the redistribution costs. Experiment s with a data-parallel polygon renderer show a performance improvement of up to a factor of 33 on unbalanced datasets and a maximum performance loss of only 27 percent on balanced datasets when using this algorithm.},
note = {LA-UR-95-1462},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Ortega, Frank; Hansen, Charles; Ahrens, James
Fast Data Parallel Polygon Rendering Proceedings Article
In: Proceedings of the 1993 ACM/IEEE Conference on Supercomputing, pp. 709–718, ACM, Portland, Oregon, USA, 1993, ISBN: 0-8186-4340-4, (LA-UR-93-3173).
@inproceedings{Ortega:1993:FDP:169627.169820,
title = {Fast Data Parallel Polygon Rendering},
author = {Frank Ortega and Charles Hansen and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/FastDataParellelPolygonRendering.pdf
http://doi.acm.org/10.1145/169627.169820},
doi = {10.1145/169627.169820},
isbn = {0-8186-4340-4},
year = {1993},
date = {1993-01-01},
booktitle = {Proceedings of the 1993 ACM/IEEE Conference on Supercomputing},
pages = {709--718},
publisher = {ACM},
address = {Portland, Oregon, USA},
series = {Supercomputing '93},
abstract = {This paper describes a parallel method for polygonal rendering ona massively pamliel SIMD machine. This method, hazed on a simple shading model, is taqeted for applications which require very fad polygon rendering for extremely large sets of polygons such as is found in many scientific visualization applications, The algorithms described in this paper are incorpomted into a library of 9D gmphics routines written for the Connection Machine. The routines am implemented on both the CM-ZOO and the CM-5. This libmry enables a acientid to display $D shaded polygons directly jhm a pamllel machine without the need to tmnamit huge amounts of data to a pod-processing rendering system.},
note = {LA-UR-93-3173},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}