2014
Nouanesengsy, Boonthanome; Woodring, Jonathan; Patchett, John; Myers, Kary; Ahrens, James
ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement Proceedings Article
In: Large Data Analysis and Visualization (LDAV), 2014 IEEE 4th Symposium on, pp. 43–50, IEEE 2014, (LA-UR-pending).
Abstract | Links | BibTeX | Tags: adaptive mesh refinement, ADR, Analysis-Driven Refinement, big data, data triage, focus+context, hardware architecture, large-scale data, parallel processing, picture/image generation, prioritization, scientific data, viewing algorithms
@inproceedings{nouanesengsy2014adr,
title = {ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement},
author = {Boonthanome Nouanesengsy and Jonathan Woodring and John Patchett and Kary Myers and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/ADRVisualization.pdf},
year = {2014},
date = {2014-01-01},
booktitle = {Large Data Analysis and Visualization (LDAV), 2014 IEEE 4th Symposium on},
pages = {43--50},
organization = {IEEE},
abstract = {Prioritization of data is necessary for managing large-scale scien- tific data, as the scale of the data implies that there are only enough resources available to process a limited subset of the data. For ex- ample, data prioritization is used during in situ triage to scale with bandwidth bottlenecks, and used during focus+context visualiza- tion to save time during analysis by guiding the user to impor- tant information. In this paper, we present ADR visualization, a generalized analysis framework for ranking large-scale data using Analysis-Driven Refinement (ADR), which is inspired by Adaptive Mesh Refinement (AMR). A large-scale data set is partitioned in space, time, and variable, using user-defined importance measure- ments for prioritization. This process creates a prioritization tree over the data set. Using this tree, selection methods can generate sparse data products for analysis, such as focus+context visualiza- tions or sparse data sets.},
note = {LA-UR-pending},
keywords = {adaptive mesh refinement, ADR, Analysis-Driven Refinement, big data, data triage, focus+context, hardware architecture, large-scale data, parallel processing, picture/image generation, prioritization, scientific data, viewing algorithms},
pubstate = {published},
tppubtype = {inproceedings}
}
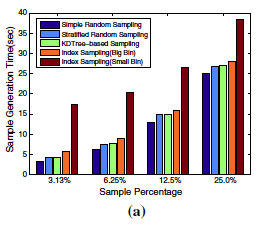
Su, Yu; Agrawal, Gagan; Woodring, Jonathan; Myers, Kary; Wendelberger, Joanne; Ahrens, James
Effective and efficient data sampling using bitmap indices Journal Article
In: Cluster Computing, pp. 1-20, 2014, ISSN: 1386-7857, (LA-UR-pending).
Abstract | Links | BibTeX | Tags: big data, Bitmap indexing, data sampling, Multi-resolution, parallel processing
@article{,
title = {Effective and efficient data sampling using bitmap indices},
author = {Yu Su and Gagan Agrawal and Jonathan Woodring and Kary Myers and Joanne Wendelberger and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/EffectiveAndEfficientDataSamplingUsingBitmapIndeces.pdf},
doi = {10.1007/s10586-014-0360-5},
issn = {1386-7857},
year = {2014},
date = {2014-01-01},
journal = {Cluster Computing},
pages = {1-20},
publisher = {Springer US},
abstract = {With growing computational capabilities of parallel machines, scientific simulations are being performed at finer spatial and temporal scales, leading to a data explosion. The growing sizes are making it extremely hard to store, manage, disseminate, analyze, and visualize these datasets, especially as neither the memory capacity of parallel machines, memory access speeds, nor disk bandwidths are increasing at the same rate as the computing power. Sampling can be an effective technique to address the above challenges, but it is extremely important to ensure that dataset characteristics are preserved, and the loss of accuracy is within acceptable levels. In this paper, we address the data explosion problems by developing a novel sampling approach, and implementing it in a flexible system that supports server-side sampling and data subsetting.We observe that to allowsubsetting over scientific datasets, data repositories are likely to use an indexing technique. Among these techniques, we see that bitmap indexing can not only effectively support subsetting over scientific datasets, but can also help create samples that preserve both value and spatial distributions over scientific datasets. We have developed algorithms for using bitmap indices to sample datasets. We have also shown how only a small amount of additional metadata stored with bitvectors can help assess loss of accuracy with a particular subsampling level. Some of the other properties of this novel approach include: (1) sampling can be flexibly applied to a subset of the original dataset, which may be specified using a valuebased and/or a dimension-based subsetting predicate, and (2) no data reorganization is needed, once bitmap indices have been generated. We have extensively evaluated our method with different types of datasets and applications, and demonstrated the effectiveness of our approach.},
note = {LA-UR-pending},
keywords = {big data, Bitmap indexing, data sampling, Multi-resolution, parallel processing},
pubstate = {published},
tppubtype = {article}
}
2011
Nouanesengsy, Boonthanome; Ahrens, James; Woodring, Jonathan; Shen, Han-Wei
Revisiting parallel rendering for shared memory machines Proceedings Article
In: Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization, pp. 31–40, Eurographics Association 2011, (LA-UR-11-02086).
Abstract | Links | BibTeX | Tags: hardware architecture, parallel processing, parallel rendering
@inproceedings{nouanesengsy2011revisiting,
title = {Revisiting parallel rendering for shared memory machines},
author = {Boonthanome Nouanesengsy and James Ahrens and Jonathan Woodring and Han-Wei Shen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/RevisitingParallelRenderingForSharedMemoryMachines.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization},
pages = {31--40},
organization = {Eurographics Association},
abstract = {Increasing the core count of CPUs to increase computational performance has been a significant trend for the better part of a decade. This has led to an unprecedented availability of large shared memory machines. Programming paradigms and systems are shifting to take advantage of this architectural change, so that intra-node parallelism can be fully utilized. Algorithms designed for parallel execution on distributed systems will also need to be modified to scale in these new shared and hybrid memory systems. In this paper, we reinvestigate parallel rendering algorithms with the goal of finding one that achieves favorable performance in this new environment. We test and analyze various methods, including sort-first, sort-last, and a hybrid scheme, to find an optimal parallel algorithm that maximizes shared memory performance.},
note = {LA-UR-11-02086},
keywords = {hardware architecture, parallel processing, parallel rendering},
pubstate = {published},
tppubtype = {inproceedings}
}
2006
Ahrens, James; Moreland, Kenneth; Geveci, Berk; Cedilnik, Andy; Favre, Jean
Remote large data visualization in the paraview framework Proceedings Article
In: Proceedings of the 6th Eurographics conference on Parallel Graphics and Visualization, pp. 163–170, Eurographics Association 2006, (LA-UR-10-02236).
Abstract | Links | BibTeX | Tags: computer graphics, parallel processing
@inproceedings{cedilnik2006remote,
title = {Remote large data visualization in the paraview framework},
author = {James Ahrens and Kenneth Moreland and Berk Geveci and Andy Cedilnik and Jean Favre},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/RemoteLargeDataVisualizationInTheParaViewFramework.pdf},
year = {2006},
date = {2006-01-01},
booktitle = {Proceedings of the 6th Eurographics conference on Parallel Graphics and Visualization},
pages = {163--170},
organization = {Eurographics Association},
abstract = {Scientists are using remote parallel computing resources to run scientific simulations to model a range of scientific problems. Visualization tools are used to understand the massive datasets that result from these simulations. A number of problems need to be overcome in order to create a visualization tool that effectively visualizes these datasets under this scenario. Problems include how to effectively process and display massive datasets and how to effectively communicate data and control information between the geographically distributed computing and visualization resources. We believe a solution that incorporates a data parallel data server, a data parallel rendering server and client controller is key. Using this data server, render server, client model as a basis, this paper describes in detail a set of integrated solutions to remote/distributed visualization problems including presenting an efficient M to N parallel algorithm for transferring geometry data, an effective server interface abstraction and parallel rendering techniques for a range of rendering modalities including tiled display walls and CAVEs.},
note = {LA-UR-10-02236},
keywords = {computer graphics, parallel processing},
pubstate = {published},
tppubtype = {inproceedings}
}
2001
Keahey, Alan; McCormick, Patrick; Ahrens, James; Keahey, Katarzyna
Qviz: a framework for querying and visualizing data Proceedings Article
In: Photonics West 2001-Electronic Imaging, pp. 259–267, International Society for Optics and Photonics 2001, (LA-UR-00-6116).
Abstract | Links | BibTeX | Tags: analytical queries, data visualization, multivariate visualization, parallel processing
@inproceedings{keahey2001qviz,
title = {Qviz: a framework for querying and visualizing data},
author = {Alan Keahey and Patrick McCormick and James Ahrens and Katarzyna Keahey},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/QvizAFrameworkForQueryingAndVisualizaingData.pdf},
year = {2001},
date = {2001-01-01},
booktitle = {Photonics West 2001-Electronic Imaging},
pages = {259--267},
organization = {International Society for Optics and Photonics},
abstract = {Qviz is a lightweight, modular, and easy to use parallel system for interactive analytical query processing and visual presentation of large datasets. Qviz allows queries of arbitrary complexity to be easily constructed using a specialized scripting language. Visual presentation of the results is also easily achived via simple scripted and interactive commands to our query-specific visualization tools. This paper describes our initial experiences with the Qviz system for querying and visualizing scientific datasets, showing how Qviz has been used in two different applications: ocean modeling and linear accelerator simulations.},
note = {LA-UR-00-6116},
keywords = {analytical queries, data visualization, multivariate visualization, parallel processing},
pubstate = {published},
tppubtype = {inproceedings}
}
Nouanesengsy, Boonthanome; Woodring, Jonathan; Patchett, John; Myers, Kary; Ahrens, James
ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement Proceedings Article
In: Large Data Analysis and Visualization (LDAV), 2014 IEEE 4th Symposium on, pp. 43–50, IEEE 2014, (LA-UR-pending).
@inproceedings{nouanesengsy2014adr,
title = {ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement},
author = {Boonthanome Nouanesengsy and Jonathan Woodring and John Patchett and Kary Myers and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/ADRVisualization.pdf},
year = {2014},
date = {2014-01-01},
booktitle = {Large Data Analysis and Visualization (LDAV), 2014 IEEE 4th Symposium on},
pages = {43--50},
organization = {IEEE},
abstract = {Prioritization of data is necessary for managing large-scale scien- tific data, as the scale of the data implies that there are only enough resources available to process a limited subset of the data. For ex- ample, data prioritization is used during in situ triage to scale with bandwidth bottlenecks, and used during focus+context visualiza- tion to save time during analysis by guiding the user to impor- tant information. In this paper, we present ADR visualization, a generalized analysis framework for ranking large-scale data using Analysis-Driven Refinement (ADR), which is inspired by Adaptive Mesh Refinement (AMR). A large-scale data set is partitioned in space, time, and variable, using user-defined importance measure- ments for prioritization. This process creates a prioritization tree over the data set. Using this tree, selection methods can generate sparse data products for analysis, such as focus+context visualiza- tions or sparse data sets.},
note = {LA-UR-pending},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Su, Yu; Agrawal, Gagan; Woodring, Jonathan; Myers, Kary; Wendelberger, Joanne; Ahrens, James
Effective and efficient data sampling using bitmap indices Journal Article
In: Cluster Computing, pp. 1-20, 2014, ISSN: 1386-7857, (LA-UR-pending).
@article{,
title = {Effective and efficient data sampling using bitmap indices},
author = {Yu Su and Gagan Agrawal and Jonathan Woodring and Kary Myers and Joanne Wendelberger and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/EffectiveAndEfficientDataSamplingUsingBitmapIndeces.pdf},
doi = {10.1007/s10586-014-0360-5},
issn = {1386-7857},
year = {2014},
date = {2014-01-01},
journal = {Cluster Computing},
pages = {1-20},
publisher = {Springer US},
abstract = {With growing computational capabilities of parallel machines, scientific simulations are being performed at finer spatial and temporal scales, leading to a data explosion. The growing sizes are making it extremely hard to store, manage, disseminate, analyze, and visualize these datasets, especially as neither the memory capacity of parallel machines, memory access speeds, nor disk bandwidths are increasing at the same rate as the computing power. Sampling can be an effective technique to address the above challenges, but it is extremely important to ensure that dataset characteristics are preserved, and the loss of accuracy is within acceptable levels. In this paper, we address the data explosion problems by developing a novel sampling approach, and implementing it in a flexible system that supports server-side sampling and data subsetting.We observe that to allowsubsetting over scientific datasets, data repositories are likely to use an indexing technique. Among these techniques, we see that bitmap indexing can not only effectively support subsetting over scientific datasets, but can also help create samples that preserve both value and spatial distributions over scientific datasets. We have developed algorithms for using bitmap indices to sample datasets. We have also shown how only a small amount of additional metadata stored with bitvectors can help assess loss of accuracy with a particular subsampling level. Some of the other properties of this novel approach include: (1) sampling can be flexibly applied to a subset of the original dataset, which may be specified using a valuebased and/or a dimension-based subsetting predicate, and (2) no data reorganization is needed, once bitmap indices have been generated. We have extensively evaluated our method with different types of datasets and applications, and demonstrated the effectiveness of our approach.},
note = {LA-UR-pending},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Nouanesengsy, Boonthanome; Ahrens, James; Woodring, Jonathan; Shen, Han-Wei
Revisiting parallel rendering for shared memory machines Proceedings Article
In: Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization, pp. 31–40, Eurographics Association 2011, (LA-UR-11-02086).
@inproceedings{nouanesengsy2011revisiting,
title = {Revisiting parallel rendering for shared memory machines},
author = {Boonthanome Nouanesengsy and James Ahrens and Jonathan Woodring and Han-Wei Shen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/RevisitingParallelRenderingForSharedMemoryMachines.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization},
pages = {31--40},
organization = {Eurographics Association},
abstract = {Increasing the core count of CPUs to increase computational performance has been a significant trend for the better part of a decade. This has led to an unprecedented availability of large shared memory machines. Programming paradigms and systems are shifting to take advantage of this architectural change, so that intra-node parallelism can be fully utilized. Algorithms designed for parallel execution on distributed systems will also need to be modified to scale in these new shared and hybrid memory systems. In this paper, we reinvestigate parallel rendering algorithms with the goal of finding one that achieves favorable performance in this new environment. We test and analyze various methods, including sort-first, sort-last, and a hybrid scheme, to find an optimal parallel algorithm that maximizes shared memory performance.},
note = {LA-UR-11-02086},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Ahrens, James; Moreland, Kenneth; Geveci, Berk; Cedilnik, Andy; Favre, Jean
Remote large data visualization in the paraview framework Proceedings Article
In: Proceedings of the 6th Eurographics conference on Parallel Graphics and Visualization, pp. 163–170, Eurographics Association 2006, (LA-UR-10-02236).
@inproceedings{cedilnik2006remote,
title = {Remote large data visualization in the paraview framework},
author = {James Ahrens and Kenneth Moreland and Berk Geveci and Andy Cedilnik and Jean Favre},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/RemoteLargeDataVisualizationInTheParaViewFramework.pdf},
year = {2006},
date = {2006-01-01},
booktitle = {Proceedings of the 6th Eurographics conference on Parallel Graphics and Visualization},
pages = {163--170},
organization = {Eurographics Association},
abstract = {Scientists are using remote parallel computing resources to run scientific simulations to model a range of scientific problems. Visualization tools are used to understand the massive datasets that result from these simulations. A number of problems need to be overcome in order to create a visualization tool that effectively visualizes these datasets under this scenario. Problems include how to effectively process and display massive datasets and how to effectively communicate data and control information between the geographically distributed computing and visualization resources. We believe a solution that incorporates a data parallel data server, a data parallel rendering server and client controller is key. Using this data server, render server, client model as a basis, this paper describes in detail a set of integrated solutions to remote/distributed visualization problems including presenting an efficient M to N parallel algorithm for transferring geometry data, an effective server interface abstraction and parallel rendering techniques for a range of rendering modalities including tiled display walls and CAVEs.},
note = {LA-UR-10-02236},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Keahey, Alan; McCormick, Patrick; Ahrens, James; Keahey, Katarzyna
Qviz: a framework for querying and visualizing data Proceedings Article
In: Photonics West 2001-Electronic Imaging, pp. 259–267, International Society for Optics and Photonics 2001, (LA-UR-00-6116).
@inproceedings{keahey2001qviz,
title = {Qviz: a framework for querying and visualizing data},
author = {Alan Keahey and Patrick McCormick and James Ahrens and Katarzyna Keahey},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/QvizAFrameworkForQueryingAndVisualizaingData.pdf},
year = {2001},
date = {2001-01-01},
booktitle = {Photonics West 2001-Electronic Imaging},
pages = {259--267},
organization = {International Society for Optics and Photonics},
abstract = {Qviz is a lightweight, modular, and easy to use parallel system for interactive analytical query processing and visual presentation of large datasets. Qviz allows queries of arbitrary complexity to be easily constructed using a specialized scripting language. Visual presentation of the results is also easily achived via simple scripted and interactive commands to our query-specific visualization tools. This paper describes our initial experiences with the Qviz system for querying and visualizing scientific datasets, showing how Qviz has been used in two different applications: ocean modeling and linear accelerator simulations.},
note = {LA-UR-00-6116},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}