2014
Nouanesengsy, Boonthanome; Woodring, Jonathan; Patchett, John; Myers, Kary; Ahrens, James
ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement Proceedings Article
In: Large Data Analysis and Visualization (LDAV), 2014 IEEE 4th Symposium on, pp. 43–50, IEEE 2014, (LA-UR-pending).
Abstract | Links | BibTeX | Tags: adaptive mesh refinement, ADR, Analysis-Driven Refinement, big data, data triage, focus+context, hardware architecture, large-scale data, parallel processing, picture/image generation, prioritization, scientific data, viewing algorithms
@inproceedings{nouanesengsy2014adr,
title = {ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement},
author = {Boonthanome Nouanesengsy and Jonathan Woodring and John Patchett and Kary Myers and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/ADRVisualization.pdf},
year = {2014},
date = {2014-01-01},
booktitle = {Large Data Analysis and Visualization (LDAV), 2014 IEEE 4th Symposium on},
pages = {43--50},
organization = {IEEE},
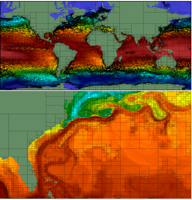
abstract = {Prioritization of data is necessary for managing large-scale scien- tific data, as the scale of the data implies that there are only enough resources available to process a limited subset of the data. For ex- ample, data prioritization is used during in situ triage to scale with bandwidth bottlenecks, and used during focus+context visualiza- tion to save time during analysis by guiding the user to impor- tant information. In this paper, we present ADR visualization, a generalized analysis framework for ranking large-scale data using Analysis-Driven Refinement (ADR), which is inspired by Adaptive Mesh Refinement (AMR). A large-scale data set is partitioned in space, time, and variable, using user-defined importance measure- ments for prioritization. This process creates a prioritization tree over the data set. Using this tree, selection methods can generate sparse data products for analysis, such as focus+context visualiza- tions or sparse data sets.},
note = {LA-UR-pending},
keywords = {adaptive mesh refinement, ADR, Analysis-Driven Refinement, big data, data triage, focus+context, hardware architecture, large-scale data, parallel processing, picture/image generation, prioritization, scientific data, viewing algorithms},
pubstate = {published},
tppubtype = {inproceedings}
}
2011
Nouanesengsy, Boonthanome; Ahrens, James; Woodring, Jonathan; Shen, Han-Wei
Revisiting parallel rendering for shared memory machines Proceedings Article
In: Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization, pp. 31–40, Eurographics Association 2011, (LA-UR-11-02086).
Abstract | Links | BibTeX | Tags: hardware architecture, parallel processing, parallel rendering
@inproceedings{nouanesengsy2011revisiting,
title = {Revisiting parallel rendering for shared memory machines},
author = {Boonthanome Nouanesengsy and James Ahrens and Jonathan Woodring and Han-Wei Shen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/RevisitingParallelRenderingForSharedMemoryMachines.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization},
pages = {31--40},
organization = {Eurographics Association},
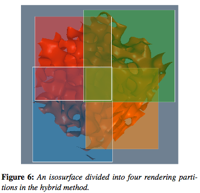
abstract = {Increasing the core count of CPUs to increase computational performance has been a significant trend for the better part of a decade. This has led to an unprecedented availability of large shared memory machines. Programming paradigms and systems are shifting to take advantage of this architectural change, so that intra-node parallelism can be fully utilized. Algorithms designed for parallel execution on distributed systems will also need to be modified to scale in these new shared and hybrid memory systems. In this paper, we reinvestigate parallel rendering algorithms with the goal of finding one that achieves favorable performance in this new environment. We test and analyze various methods, including sort-first, sort-last, and a hybrid scheme, to find an optimal parallel algorithm that maximizes shared memory performance.},
note = {LA-UR-11-02086},
keywords = {hardware architecture, parallel processing, parallel rendering},
pubstate = {published},
tppubtype = {inproceedings}
}
Nouanesengsy, Boonthanome; Woodring, Jonathan; Patchett, John; Myers, Kary; Ahrens, James
ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement Proceedings Article
In: Large Data Analysis and Visualization (LDAV), 2014 IEEE 4th Symposium on, pp. 43–50, IEEE 2014, (LA-UR-pending).
@inproceedings{nouanesengsy2014adr,
title = {ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement},
author = {Boonthanome Nouanesengsy and Jonathan Woodring and John Patchett and Kary Myers and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/ADRVisualization.pdf},
year = {2014},
date = {2014-01-01},
booktitle = {Large Data Analysis and Visualization (LDAV), 2014 IEEE 4th Symposium on},
pages = {43--50},
organization = {IEEE},
abstract = {Prioritization of data is necessary for managing large-scale scien- tific data, as the scale of the data implies that there are only enough resources available to process a limited subset of the data. For ex- ample, data prioritization is used during in situ triage to scale with bandwidth bottlenecks, and used during focus+context visualiza- tion to save time during analysis by guiding the user to impor- tant information. In this paper, we present ADR visualization, a generalized analysis framework for ranking large-scale data using Analysis-Driven Refinement (ADR), which is inspired by Adaptive Mesh Refinement (AMR). A large-scale data set is partitioned in space, time, and variable, using user-defined importance measure- ments for prioritization. This process creates a prioritization tree over the data set. Using this tree, selection methods can generate sparse data products for analysis, such as focus+context visualiza- tions or sparse data sets.},
note = {LA-UR-pending},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Nouanesengsy, Boonthanome; Ahrens, James; Woodring, Jonathan; Shen, Han-Wei
Revisiting parallel rendering for shared memory machines Proceedings Article
In: Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization, pp. 31–40, Eurographics Association 2011, (LA-UR-11-02086).
@inproceedings{nouanesengsy2011revisiting,
title = {Revisiting parallel rendering for shared memory machines},
author = {Boonthanome Nouanesengsy and James Ahrens and Jonathan Woodring and Han-Wei Shen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/RevisitingParallelRenderingForSharedMemoryMachines.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization},
pages = {31--40},
organization = {Eurographics Association},
abstract = {Increasing the core count of CPUs to increase computational performance has been a significant trend for the better part of a decade. This has led to an unprecedented availability of large shared memory machines. Programming paradigms and systems are shifting to take advantage of this architectural change, so that intra-node parallelism can be fully utilized. Algorithms designed for parallel execution on distributed systems will also need to be modified to scale in these new shared and hybrid memory systems. In this paper, we reinvestigate parallel rendering algorithms with the goal of finding one that achieves favorable performance in this new environment. We test and analyze various methods, including sort-first, sort-last, and a hybrid scheme, to find an optimal parallel algorithm that maximizes shared memory performance.},
note = {LA-UR-11-02086},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}